A sweet (pun intended) article about what I learned from the book "Monolith to Microservices" regarding cohesion, coupling, and refactoring methods, demonstrated with real-life examples from a chocolate factory.
Prologue - How Did I Get the Idea for This Article?
In 2021, I read the book "Monolith to Microservices" by Sam Newman (2019). The book explains how to transition from monolithic systems to microservices architecture. I read it because, in my team back then, we worked on a huge monolith, and I had a task to write the first new microservice. I had only heard the buzzword "Microservice" before but never really understood its real significance until I read the book.
Since then, I've had the idea of passing on the insights I gained from reading this (245 pages long!) book, clearly and easily.
I wanted to allegorize this architectural problem with real-life examples. After all, software engineering is just like other engineering industries, except for the fact that the solutions we build are so easy to manufacture and deliver.
The problem was that the internet is full of examples of how Microservices architecture is just like a modern car factory and how high coupling is just like how a submarine is built, and well… As a stereotypical girl, this couldn’t be further from my world of associations!
So I realized it could be demonstrated with something much more appealing - a Chocolate Factory!, inspired by one of my favorite movies ever - Charlie and the Chocolate Factory (The 2005 version with Johnny Depp, obviously).

Willy Wonka and the Chocolate Monolith
When Willy Wonka just founded his Chocolate initiative, he did all the work himself. He bought the chocolate, made the candy bars, crafted the coffee toffee candies, wrapped them, and probably also took care of packing and selling.
It all worked for him, and the sales were nice, so the initiative turned into a little chocolate shop with a few employees. Not a long time passed before Willy Wonka's business became a successful company, so he decided to open his factory.
However, as time passed, some things started to squeak. Wonka noticed that the time to market is longer than expected, that there are bottlenecks in the process, and don’t get me started on those lazy Oompa-Loompas. In addition, it’s not as easy as it was to sandbox new candy technologies, for example, exchanging the cocoa beans manufacturer or composing a new gum that tastes like a whole meal (I’m still craving this one!).
So Wonka decides to make a change, break the Monolith, and transition his factory to a Microservices architecture.
Wisely, Wonka did not choose this architecture right from the beginning. When launching a new start-up, you often don’t know yet the domains and the different processes that will drive your business; therefore, it’s better to wait a bit until you’re done pivoting and the product structure is stabilized.
Let’s Move to Code
Assuming our factory is virtual, it probably looks something like this, with a few threads running independently.
class ChocolateStore {
void RunStore() {
while(true) {
// Take care of orders
var order = pullOrder();
var chocolateBars = chocolateBarsStorage.Read(order.barsCount);
var toffees = toffeeStorage.Read(order.toffeeCount);
Ship(order.address, chocolateBars, toffees)
}
}
}
class ProduceChocolateBars {
void ProduceBars() {
while(true) {
var order = pullOrder();
var chocolate = chocolateStorage.Read(5);
var chocolateBars = new ChocolateBars(chocolate);
chocolateBarsStorage.Save(chocolateBars);
}
}
}We can identify a few problems here:
- If we wanted to try a new cocoa beans provider or a roasting technique, this would be almost impossible, as every
CandyProduceris reaching directly to the chocolate storage. Meaning, there’s a high coupling between the production and the storage.
- If the
chocolateBarsStoragehas high traffic all of a sudden, it will slow down the entire order cycle. Meaning, it’s not scalable.

Planning the Factory Refactor
The first step after deciding to split a monolith is to decide on a metric, a number we will use to prove that the transition worked and was worth the effort.
In Wonka’s case, it can be the factory’s annual revenues, the amount of new candies invented per year, or even employee satisfaction grade. The important thing is to focus on the metric and the goal we would love to improve the most.
The second step is to start and untie the knots and understand the different domains of the business. Each such domain will move to be a new department in the factory (or a new microservice in our case).
Eventually, we want to hold a map of all the business domains and the relations between them. To achieve that, we can use something the book calls an “Event Storm”, meaning, listing all “events” we can think of that happen within our business.
For example:
- An order is made from a store
- A chocolate bar is finished wrapping
- A truck is shipped to a store
After we have that list, we can start and draw our map. In our case, it should look roughly like this:
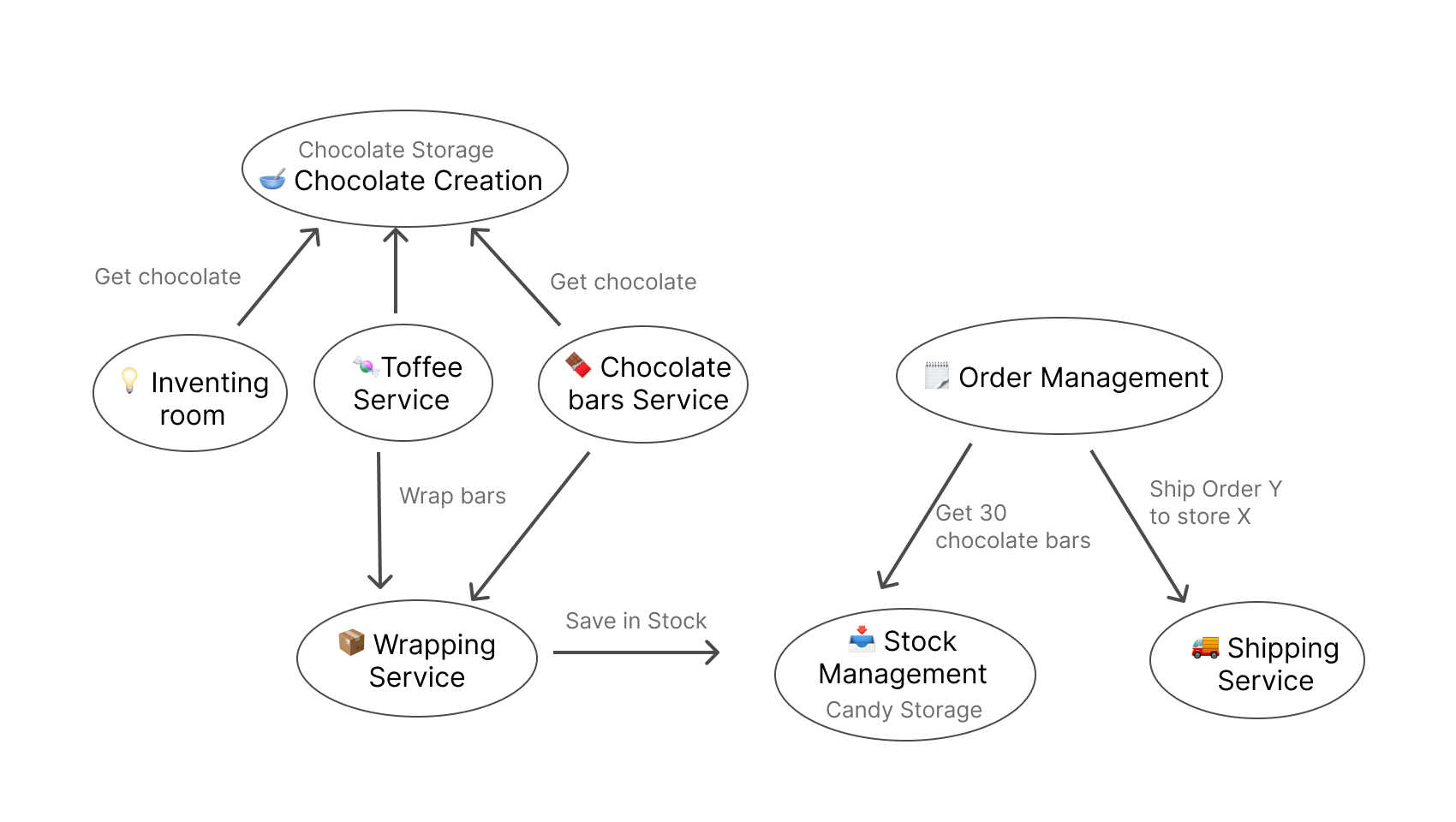
Each such circle is a different domain, that can potentially become a separate service.
However, just because there are different domains, doesn’t mean everything should be separated immediately—quite the contrary. We would like to gradually change the structure to examine the change and improve as we go, refactoring one piece at a time.
At each step, we will assess which part will give us the best ROI for transitioning it into a service. that would be a combination of 2 factors: A low amount of incoming edges, which reflects that no other part relies on them (like in the Inventing Room), and a high frequency of changes or issues, or high motivation for a logic replacement. For example, if we know that we want to change the way we take orders, the Order Management service can be a good fit.
Migration Methods
Now that we decided on the first service we are going to split, we need to decide on our strategy. There are a few refactoring methods that are useful in our case.
Strangler Fig
According to this method, we will write a new piece of code, and the old and new code will live side by side for a while, as the new code will start to handle more and more of the traffic as time passes, allowing us to gradually deploy our change.
How it’s done?
First of all, we will create a new service, in this case for our Order Management. We can even deploy the new service right away - we don’t need to implement anything yet because no one is aware of this service!
Now we can continue to identify the service’s interface, just returning 501 NOT IMPLEMENTED on each endpoint. In our service, we only have one endpoint in our interface: Place order.
As you notice, it’s all about short-lived branches in this method, which I like (will elaborate more in the end).
After we implement the logic of placing orders, we can start referring our customers to use the new ordering service instead of the old one. To utilize that we will use a Proxy, which upon an environment variable/feature flag will refer all calls to the old service, to the new one.
Here's an example of an Nginx proxy configuration we can use:
location /order-management/ {
proxy_pass http://order-management/orders/;
}Bonus fact: The name Strangler Fig comes from the Strangler Fig plant, which wraps around a tree, and strangles trees slowly until it kills their hosts 😲. Sounds like material for a horror movie.

Branch by abstraction
This method is adjusted to cases where the monolith is dependent on the service we are transitioning, which is the case we will face most of the time.
Let’s take for example the Chocolate creation service.
Currently, in our code, whenever some process needs chocolate, they just go ahead and take chocolate from the storage.
var chocolateBars = chocolateBarsStorage.Read(5);This makes the task of building a “Chocolate creation” service seem almost impossible.
So we’ll start by identifying all of the consumers of chocolate, and replacing them with an abstraction.
By an abstraction I mean, an interface that will give us the same results, but the consumers won’t be aware of its inner implementation. For example:
interface IChocolateProvider {
List<Chocolate> GetChocolate(int amount);
}Now we can implement the abstraction. One implementation will act exactly like the code is acting now, and the other one will refer to our new logic, which is not implemented yet.
We will also use a factory method (oh boy, too many factories today) to return us the correct implementation.
class OldChocolateProvider: IChocolateProvider {
List<Chocolate> GetChocolate(int amount) {
return chocolateBarsStorage.Read(amount);
}
}
class NewChocolateProvider: IChocolateProvider {
List<Chocolate> GetChocolate(int amount) {
throw new NotImplementedError();
}
}
// Factory:
IChocolateProvider GetChocolateProvider() {
return new OldChocolateProvider()
}The third part will be to replace all usages of chocolate, to use the abstraction.
var chocolateProvider = GetChocolateProvider()
var chocolateBars = chocolateProvider.GetChocolate(5);This is the hardest part of this refactoring method, and now that the code is well-refactored, we are free to start implementing our new service, keeping again on short-lived branches.
Only when we are done implementing our service, we can start referring calls to our new implementation, changing only one place - the GetChocolateProvider! We can make it rely on a feature flag, a configuration, etc.
And of course, don’t forget to remove the old implementation once you are done with the process, to keep your code nice and clean.
A word on short-lived branches
It’s tempting to develop a feature in a huge branch and merge it only when the feature is done. But it has multiple advantages for keeping your branches small, even at the price of having TODOs and TBDs in your codebase.
First, it’s helping with code reviews. It’s very intuitive that the smaller the change, the easier it is to review. Secondly, it reduces the chances of huge merge conflicts, in case you are working in an existing code base. Lastly, you get to receive early feedback, both from reviewers and from CI, tests, and automation, allowing you to improve along the way and get the best result eventually.

To summarize
I hope you liked this article and the unique perspective on the microservices transition!
I still haven’t decided if there will be a part B for this article that focuses on how to split Databases as part of the Microservices transition. If you feel like it can help you out - don’t hesitate to let me know